Mein Newsletter schreibt sich selbst: Eine vollautomatische Musik-Weltreise
Streaming-Algorithmen zeigen mir vor allem mehr von dem, was ich schon kenne. Dabei entdecke ich eigentlich gerne auch mal etwas komplett Neues.
Aus dieser Idee entstand Offbeat Odyssey.
Ich wollte ein System bauen, das mich regelmässig mit neuen musikalischen Impulsen versorgt. Am besten vollautomatisch: recherchiert, kuratiert und aufbereitet von KI, ohne selbst viel Zeit investieren zu müssen. Und mit bewusst zufälligen Empfehlungen statt «More-of-the-same».
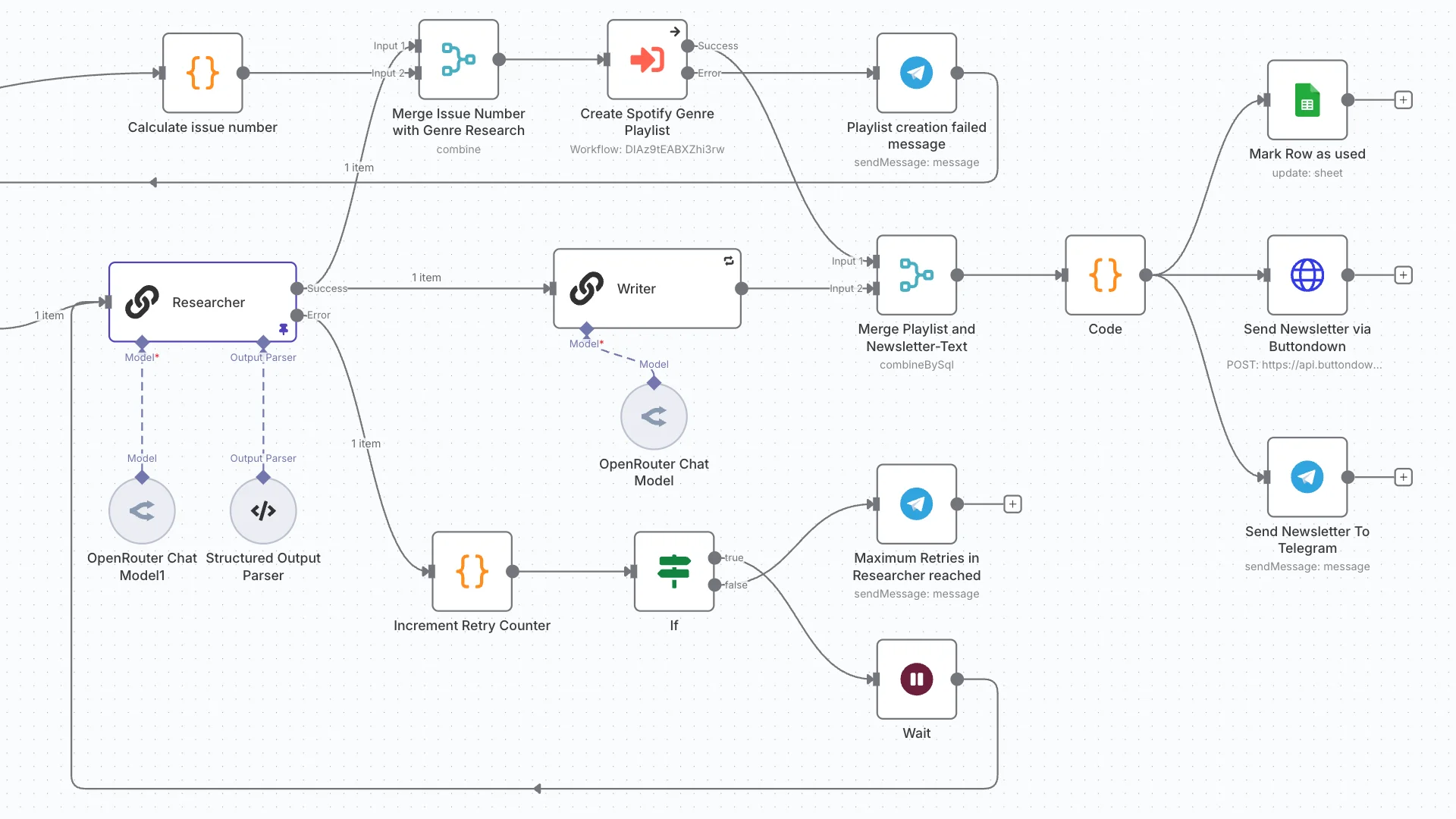
Nach etwas Recherche habe ich mich für folgenden Tech-Stack entschieden: n8n als Workflow-Engine, OpenRouter für flexible Modell-Auswahl, Spotify API für Playlists, Buttondown für Newsletter-Versand, Telegram für die Vorschau und System-Nachrichten. Im folgdenden ein paar Details zum Aufbau.
Der Workflow: 5 Schritte vom Genre zu Inbox
1. Genre-Lotterie
Die Basis bildet eine Liste der 1’000 populärsten Spotify-Genres. In jeder Ausgabe wählt der Workflow per Zufall eines aus. Einfach, aber entscheidend für mein Konzept: es verhindert, dass ich in meiner eigenen «Musik-Filterblase» hängen bleibe.
2. LLM als «Musikjournalist»
Ist das Genre gewählt, bekommt ein LLM via OpenRouter den Auftrag:
- «Recherchiere» Hintergründe zum Genre: Ursprung, kultureller Kontext, charakteristische Merkmale
- Identifiziere die wichtigsten Künstler:innen und ihre prägendsten Songs/Alben
Der Output ist ein sauber strukturiertes, maschinenlesbares JSON, bereit für den nächsten Schritt.
Für diese Rolle nutze ich zurzeit Claude Sonnet 4.5. Durch die niedrige Kadenz (2x pro Woche) sind die Kosten minim. Während der Entwicklungsphase kam Llama 3.3 (gratis) zum Einsatz, der Wechsel war dank OpenRouter denkbar einfach.
3. Von Daten zu Story
Zweiter LLM-Call: Aus der Recherche wird ein lesbarer Newsletter-Text. Hier kommt der kreative Teil: Das Modell verdichtet Facts zu einer Erzählung, die Lust machen soll, auf Play zu drücken.
Im Moment nutze ich dafür Claude Haiku 4.5. Anfänglich war auch hier Llama 3.3 im Einsatz, das Modell hat aber nicht ganz so gut auf meine Befehle gehört. Beispielsweise hat es oft platte Phrasen wie «XY is more than a genre» verwendet, trotz ausdrücklichem Verbot.
4. Playlist-Generierung via Spotify API
n8n hat native Spotify-Nodes, was diesen Schritt ziemlich einfach macht: Der Workflow sucht via API die recherchierten Songs aus dem JSON, erstellt eine neue Playlist und befüllt sie automatisch.
5. Human-in-the-Loop via Telegram
Bevor der Newsletter rausgeht, bekomme ich eine Telegram-Nachricht mit einer Preview. Hier kann ich kurz checken: Macht die Playlist Sinn? Hat das LLM halluziniert? Passt der Text? Bei Bedarf kann ich den Prozess noch einmal ankicken.
Das System schickt mir auch allfällige Fehlermeldungen via Telegram. Seit dem Umstieg auf die robusteren Anthropic-Modelle hatte ich aber noch keinen Unterbruch im Workflow.
Von der Testphase zum Newsletter
Anfangs war das Ganze nur für mich. Aber ich merkte bald, dass das ganz gut funktioniert. Ich hatte Genres entdeckt, von denen ich noch nie gehört hatte – Vallenato aus Kolumbien, Bedroom-Soul oder Lilith. Musik, der ich sonst wohl nie begegnet wäre. Wieso also nicht mit der Welt teilen?
Also suchte ich nach einem Newsletter-Provider mit ordentlicher API. Die habe ich aber bei den üblichen Newsletter-Plattformen nicht gefunden (oder nur in Bezahl-Versionen). Buttondown bietet jedoch eine gut dokumentierte Schnittstelle, auch in der Gratis-Version.
📬 Neugierig geworden? Hier kannst du dich für den Newsletter anmelden: buttondown.com/offbeat-odyssey
Ist das jetzt AI Slop?
KI-generierter Content hat einen schlechten Ruf, zurecht. Die Grenze zwischen sinnvollem Tool und seelenlosem Spam ist schmal, und dieser Newsletter bewegt sich mit seinem wiedergekäuten Musik-Wissen irgendwo an dieser Grenze.
Ich meine aber, dass das hier durchgeht, weil der Haupthinhalt – die Musik – echt ist. Zumindest in den meisten Fällen…
Verbesserungen und Fazit
1. Error-Handling
Ganz am Anfang verwendete ich ein Deepseek-Modell, das regelmässig API-Timeouts produzierte, manchmal über mehrere Minuten hinweg. Andere Modelle liefen mit demselben Prompt stabil. Das zeigt: Die Modellwahl hat direkten Einfluss auf die Zuverlässigkeit.
Trotz des Modell-Wechsels baute ich für solche Fälle ein eigenes Error-Handling ein. Ich nutze dafür Retry-Loops mit exponentiell steigenden Wartezeiten zwischen den Anfragen. Das unterscheidet sich vom n8n-Standard, der alle paar Sekunden eine Anfrage schickt und nach ein paar erfolglosen Versuchen den Workflow abbricht. So bleibt das System robust, falls künftig ähnliche Probleme auftreten.
2. Halluzination und falsche Songs
Halluzinationen kommen vor, wenn auch relativ selten. Das Recherche-LLM kriegt als Input nur den Genre-Namen (bspw. Dancehall) und eine kurze Beschreibung (bspw. Jamaican dance music with reggae influences), den Rest saugt es sich aus den Fingern. Mit etwas mehr Kontext, etwa spezifischen Einträgen in Musik-Lexika, liesse sich die Akkuratesse wohl noch erhöhen.
Wenn Songs und/oder Bands sehr ähnlich heissen oder das gewünschte Lied nicht auf Spotify zu finden ist, landen auch mal unpassende Stücke in der Playlist. Das System pickt sich jeweils das erste Resultat aus der Suche heraus. Etwas zusätzliche Verifikation oder Logik könnte hier Abhilfe schaffen.
3. Technik < Idee
Einmal mehr wahr ich erstaunt, wie schnell sich solche Dinge mittlerweile umsetzen lassen. Natürlich kam auch beim Programmieren KI zum Einsatz. Noch vor 2-3 Jahren wären solche Abendstunden-Nebenprojekte wegen des Programmieraufwandes irgendwann versandet. Mit Vide-Coding hatte ich jedoch schnell einen Prototyp beisammen. Klar brauchts bis zum fertigen Produkt noch etwas mehr Know-How, aber die technische Barriere ist stark gesunken. Es kommt also mehr denn je auf die guten Ideen an.